在微服务架构中,服务数量激增、部署环境复杂,一个可靠的监控系统不再是可选项,而是保障系统稳定、高效运行的基石。它如同信息系统的“眼睛”和“耳朵”,是运行维护服务的核心组成部分。本文旨在分享如何从零开始,搭建一个能够洞察全局、快速定位问题的可靠监控系统。
一、监控系统的核心目标与原则
在搭建之前,必须明确监控的目标不仅是“发现问题”,更是“预防问题”和“辅助决策”。一个可靠的监控系统应遵循以下原则:
- 全面性:覆盖应用、服务、容器、主机、网络、中间件等所有层面。
- 实时性:数据采集、处理和告警的延迟要足够低,以便快速响应。
- 关联性:能将跨服务、跨组件的指标和日志关联起来,形成完整的调用链视图。
- 可扩展性:能够适应微服务数量的动态增长和技术的演进。
- 可视化与可操作性:数据应以直观的仪表盘呈现,告警信息应具备清晰的上下文,便于运维人员迅速行动。
二、监控系统架构分层搭建
一个典型的微服务监控系统通常分为以下四层:
1. 数据采集层
这是监控的源头。需要在应用代码和基础设施中埋点,采集各类数据:
- 指标(Metrics):如服务的QPS、响应时间、错误率、CPU/内存使用率等。常用采集工具有Prometheus的各类Exporter、Micrometer(Java应用)等。
- 日志(Logs):应用程序输出的结构化日志(如JSON格式)。推荐使用Filebeat、Fluentd等日志采集器。
- 追踪(Traces):记录单个请求在分布式系统中流转的完整路径。可采用OpenTelemetry标准,集成Jaeger或Zipkin。
2. 数据传输与聚合层
将分散采集的数据汇聚到中心。考虑到微服务环境的动态性,通常需要一个轻量级的消息队列或流处理平台作为缓冲,如Kafka。这可以避免数据洪峰冲垮后端存储,并实现解耦。
3. 数据存储与分析层
根据数据类型选择合适的存储,这是系统可靠性的关键:
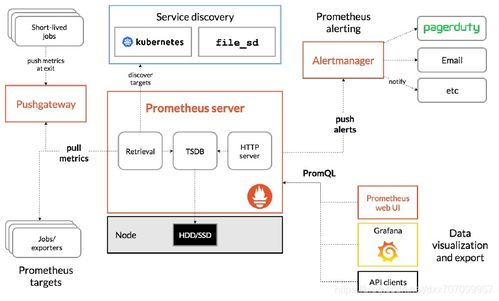
- 时序数据存储:用于存储指标数据,要求具备极高的写入和查询效率。Prometheus TSDB是其自带的优秀存储,长期历史数据可存入Thanos或VictoriaMetrics,亦或使用InfluxDB、TimescaleDB。
- 日志存储与分析:需要强大的全文检索和聚合分析能力。Elasticsearch是当前的主流选择,与Kibana搭配构成强大的日志平台。
- 追踪数据存储:Jaeger、Zipkin均有自己的存储后端,也可选择支持OpenTelemetry的通用存储。
4. 可视化与告警层
这是监控价值的最终体现。
- 可视化:Grafana是目前最流行的指标可视化工具,它能灵活地连接多种数据源(如Prometheus、Elasticsearch)创建丰富的仪表盘。Kibana则专注于日志和追踪数据的可视化。
- 告警:告警规则应分层分级。Prometheus Alertmanager可以很好地管理基于指标的告警规则,进行分组、抑制和路由(如发送到钉钉、企业微信、PagerDuty)。对于日志和追踪中的模式匹配告警,可使用ElastAlert或Grafana的告警功能。
三、关键技术栈选型与集成示例
一个经典、高性价比的开源监控技术栈组合是:
- 指标监控:Prometheus + Grafana
- 日志监控:ELK/EFK Stack (Elasticsearch, Logstash/Fluentd, Kibana)
- 分布式追踪:Jaeger 或 Zipkin
- 基础设施监控:Node Exporter (主机), cAdvisor (容器)
所有应用应通过OpenTelemetry SDK进行埋点,统一采集指标、日志和追踪信号,并将其导出到对应的后端。
四、构建可靠性的关键实践
- 监控系统自身需要被监控:用另一套独立的、更轻量的监控系统来监控核心的监控组件(如Prometheus、Elasticsearch集群的健康状态),避免出现“监控盲区”。
- 定义清晰的SLO/SLI:基于业务目标定义服务等级目标(SLO)和指标(SLI),如“API接口99.9%的请求延迟低于200ms”。监控应围绕SLO展开,告警应在SLO可能被违反前触发。
- 告警的“黄金信号”与智能化:重点关注流量、延迟、错误和饱和度这四大黄金信号。逐步引入基于机器学习的异常检测(如使用Prometheus的Prometheus ML或外接工具),减少误报和噪音。
- 建立完善的On-Call与故障响应流程:可靠的监控必须配合有效的人员流程。告警应能自动分派到责任人,并附带清晰的排障指引和上下文(如关联的日志、变更记录)。
- 容量规划与高可用部署:监控数据量会快速增长,必须对存储进行容量规划。核心组件如Prometheus、Alertmanager、Elasticsearch都应以集群模式部署,确保高可用。
五、
搭建一个可靠的微服务监控系统是一个持续迭代的过程,而非一蹴而就的项目。它始于清晰的监控目标,成于分层、可扩展的技术架构,最终固化为团队日常运维的流程与文化。从核心业务指标和基础设施健康度入手,逐步完善日志、追踪等可观测性支柱,最终构建起一个能够预测风险、快速定位、辅助优化的立体监控体系,这才是微服务时代信息系统运行维护服务的坚实保障。
(本文为学习笔记与实践,技术选型仅供参考,请根据实际场景评估决策。)